Playground
LLM Foundry's playground lets you interact with large language models. It offers both a simple and advanced mode to cater to different user needs.
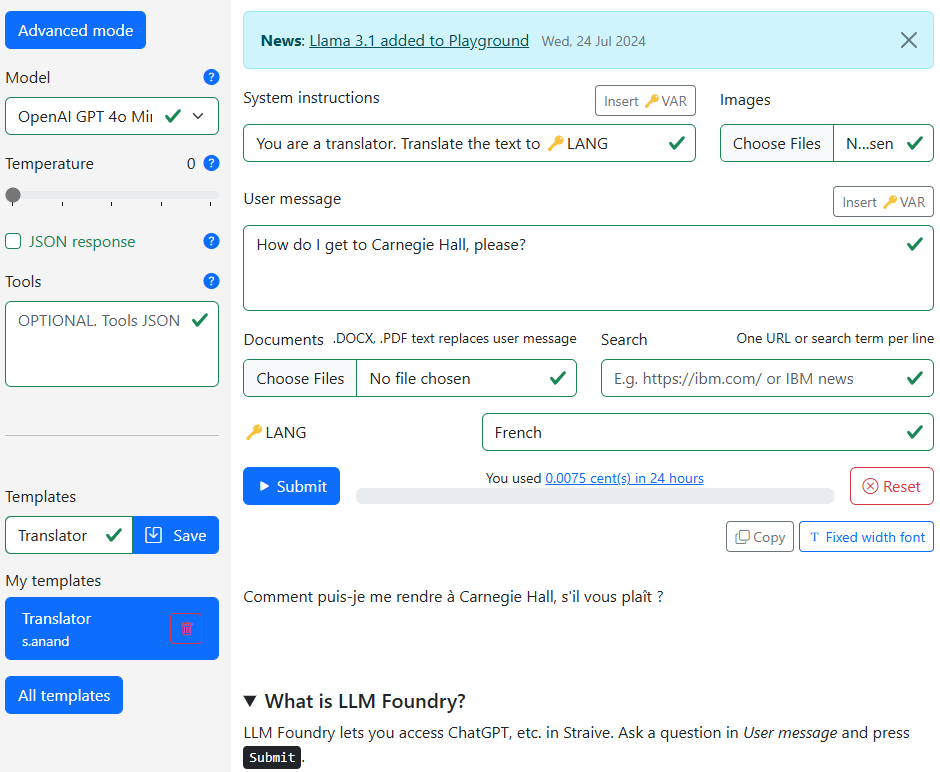
Advanced Mode
This button lets you switch between Simple and Advanced modes. Advanced mode gives you more features and controls.
User Message
Enter your prompt or question here. This is the main input for interacting with the model. Examples:
- "Correct the spelling and grammar of the following text."
- "Write a Python script to crawl all top level pages from https://reddit.com."
- "Summarize the key points of the attached document."
- "Translate the following text to French."
- "Compare these 2 similar images and describe the differences."
See the prompting guide for better prompts.
Model
Choose the LLM you want to use. Models with the best performance/price ratio have a green 🟢 next to them.
- Start with the cheapest 🟢 model
- If it doesn't work well, proceed to the next cheapest 🟢 model
Use the Model Picker to select the right model based on features.
System Instructions
These guide the model's behavior throughout the conversation. The default is "You are a helpful assistant."
When writing apps, explain what you want the model to do here, and pass the user input as the user message.
Temperature
Adjust the temperature to control the creativity of the responses.
- Lower temperatures generate more predictable responses
- Higher temperatures generate more creative responses
Temperature ranges from 0 to 2 for most models, but for the Claude family, it ranges from -1 to +1.
JSON Response
If checked, the response will be formatted as JSON, which is useful for API integration.
JSON Schema
Optionally, specify the JSON format / schema you want the output in.
- Enable "JSON response" checkbox
- Describe structure in schema box (e.g. "I want an array of objects with
nameandageproperties") - Click "Generate JSON schema". This will replace your text with a JSON schema valid for the chosen model.
Attachments
You can upload files (depending on the model):
- Images: JPEG, PNG, WEBP, or GIF. We resize images to 1024x1024 pixels to save costs. Use for:
- Reading text (OCR)
- Finding objects
- Reading charts
- Checking/validating images
- Providing screenshots as context
- Audio: MP3, WAV, M4A, etc. (Only Gemini models support audio). Use for:
- Transcribing audio with speaker diarization
- Creating meeting minutes
- Extracting action items
- Analyzing customer sentiment
- Answering questions about audio content
- Video: MP4, 3GP, etc. (Only Gemini models support video)
- Documents: PDF, DOCX, and text files including:
- Code: .py, .js, .sql, .java, etc.
- Data: .csv, .json, .yaml, etc.
- Text: .txt, .md, .html, etc.
- Subtitles: .srt, .vtt
Attachments
You can send images, audio, video, or documents to the model (depending on the model).
Files can be uploaded from:
- Your computer using the file picker
- Google Drive using the Google Drive button.
- If you see "Google hasn't verified this app" click on the tiny "Advanced" link
- Then click on the tiny "Go to straive.com (unsafe)" link
- Clipboard by pasting images directly
Supported formats are:
- Images: JPEG, PNG, WEBP, or GIF. We resize images to 1024x1024 pixels to save costs. (Only some models support images). You can use it for:
- Reading text (OCR)
- Finding objects (Object detection)
- Reading charts
- Checking or validating images
- Providing screenshots as context, etc.
- Audio: MP3, WAV, M4A, etc. (Only Gemini models support audio processing). You can use it for:
- Transcribing audio to text with speaker diarization
- Creating meeting minutes and extracting action items
- Analyzing customer sentiment from audio clips
- Answering questions about audio content
- Video: MP4, 3GP, etc. (Only Gemini models support video processing)
- Documents: (Only Gemini models support documents)
- Content: .docx, .pdf, .txt, .md, etc.
- Code: .py, .js, .sql, .java, etc.
- Data: .csv, .json, .yaml, etc.
- Text: .txt, .md, .html, etc.
- Subtitles: .srt, .vtt
The model looks at these images and answers you. You can use it to find objects, read text, read charts, check or validate images, provide screenshots as context, etc.
Only some models support vision. For other models, this option is disabled.
Documents
The "Documents" file input works differently from attachments. Documents are converted to text in the browser and then sent to the model. (Attachments send the original file content to the model.) This means:
- They work with all models.
- Only the text content of the documents is sent to the model.
You can upload .DOCX or .PDF files from your computer. Their text will replace the user message, deleting any previous user message you had.
Logprobs
For models that support it (like GPT), enable the "Logprobs" switch. This shows the probability of each token in the response.
See logprobs for more details.
RAG
For models that support it (like GPT), enable the "RAG" switch. This shows the probability of each token in the response.
See RAG for more details.
Search toggle
For models that support it (like Gemini), enable the "Search" toggle.
This will
- Automatically create search queries
- Search the web based on these queries (e.g. Gemini models use Google)
- Include the results in the model's input
- Cite the sources in the response
This is useful for real-time information, news or data alerts, etc.
This feature can be accessed via the API, too. See the Code button
Search
You can enter one or more lines of search terms or URLs in the "Search" box.
For example:
- Reuters news
- https://www.bbc.com/news
For each search term, the playground will fetch 3 results via the Google Custom Search API. The snippets are passed to the model.
For each URL, the playground will fetch the contents as Markdown.
However, some pages (like bbcnews.com) have multiple articles. In that case, increase the "# Items" from 1 to 5 (or any reasonably small number). The playground will extract the first 5 (or "# Items") links from the main body and fetch each as Markdown.
The playground uses the Readability algorithm to extract the main content.
Download
After receiving a response, you can:
- Download to download the prompts and response as a Markdown file.
- Download .DOCX to downlload as a Word (.docx) file with formatted response
- Download .CSV to download all tables in the response as CSV files
Copy
Click the Copy button to copy the response as text and formatted HTML. You can paste this in emails, Word / Google Docs, etc. with proper formatting.
Raw Text
Click the Raw text button to toggle between the formatted response and raw text response.
The response is formatted as Markdown by default. Clicking this will show the exact text output from the model.
Code
The Code button shows how to automate the request you just made via an API. This shows code in 3 languages:
- cURL. Use this in the terminal. This is the quickest way to test the API.
- Python. Use this in a Python script. It uses the
requestslibrary but your can usehttpxor any other HTTP library. - JavaScript. Use this in the browser or in Node.js. It uses the
fetchAPI.
Cost Stats
Displays the cost statistics of your usage, helping you keep track of expenses.
- Shows cents used in last 24 hours
- $1.00 daily limit by default
- Expensive models are disabled when limit reached
- Progress bar shows usage vs limit
- Links to detailed usage history
Variables
Use 🔑VAR placeholders in prompts to insert variables for customized responses. This is especially useful for API integration.
- Click "Insert 🔑VAR" next to System/User message
- Replace VAR with your variable name (e.g., 🔑NAME)
- Enter values in the Variables section below
- Values replace placeholders when submitted
This is useful for:
- Templating prompts
- API integration via the template API
- Batch processing
Templates
Select from saved templates to quickly input pre-defined prompts and settings. Useful for recurring tasks.
- Set up your prompt (model, temperature, etc.)
- Enter a template name
- Click Save to store the template
- Load templates from My Templates
Templates save the model selection, temperature, system instructions, JSON settings, and variables.
My Templates
This list shows your saved templates. You can save new templates or delete existing ones for quick access to commonly used settings.
All Templates
A link to the templates page that shows all templates shared by the LLM Foundry community.
Submit
Click to submit your prompt to the model. This initiates the processing of your request.
Reset
Click to reset all fields to their default values. This clears the model, temperature, system instructions, user message, etc.
Notifications
Displays important updates and news related to LLM Foundry. For example, "Llama 3.1 added to Playground."