RAG
RAG (Retrieval Augmented Generation) helps models answer questions about long documents by breaking them into chunks and using only the most relevant parts.
For example, when given a long annual report and asked "Does this company have an ESG policy?", RAG will:
- Split the document into chunks, e.g. of ~2000 characters
- Find chunks most relevant to ESG and policy
- Send only the top chunks to the model, e.g. top 10 chunks
- Generate an answer based on those chunks
This helps the model:
- Handle documents longer than its context window
- Focus on relevant information
- Provide more accurate answers
- Cite sources correctly
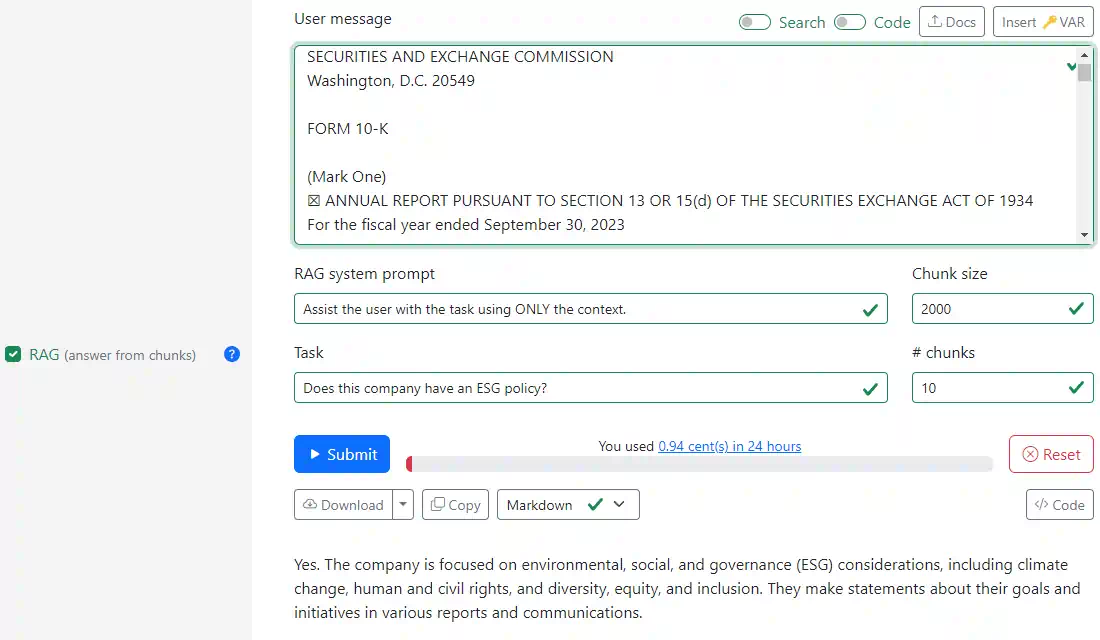
Using RAG
On the Playground, enable the RAG checkbox and:
- Paste your (long) document in the User message box
- Set your Task (e.g. "Does this company have an ESG policy?")
- Adjust settings if needed:
- Chunk size: Length of text segments (default: 2000)
- # chunks: Number of relevant chunks to use (default: 10)
- System prompt: Instructions for the model (default: "Assist the user with the task using ONLY the context")
You can use this to:
- Query long documents. Ask questions about books, reports, or documentation
- Summarize sections. Get summaries of specific topics from a large document
- Find relevant parts. Locate sections most relevant to your question
- Compare sections. Ask about relationships between different parts of a document
Note: RAG disables system instructions and attachments since it uses its own prompting strategy.