Extract
LLM Foundry's Classify Tool helps you categorize documents by topic. You can use this to:
- Group survey responses to uncover major themes and sentiments.
- Find topics from employee feedback.
- Categorize support tickets to streamline customer service.
- Identify trending topics in social media posts.
- Classify research papers by topic for literature reviews.
- Organize meeting notes into key themes for better project management.
- Categorize user comments on articles for content improvement.
- Segment email inquiries to automate responses and improve efficiency.
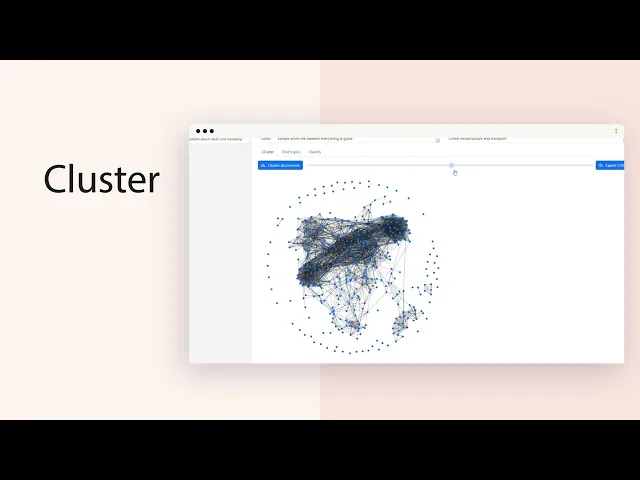
Documents
Enter the text you want to classify, cluster, or find topics for. Each line represents a different document. You can paste (or type in):
- One column of text from Excel or Google Sheets. Wrap in "quotes" if they contain tabs or newlines.
- Multiple columns of text (tab-delimited) from Excel or Google Sheets. Only the LAST column will be used, but other columns are retained for reference.
If your data has a header row, select Header in first row.
Topics
OPTIONAL: If you know the topics you want to categorize documents into, enter them here. Each line represents a different topic. You can paste (or type in):
- One column of text from Excel or Google Sheets. Wrap in "quotes" if they contain tabs or newlines.
- Multiple columns of text (tab-delimited) from Excel or Google Sheets. Only the LAST column will be used, but other columns are retained for reference.
If your data has a header row, select Header in first row.
Cluster
This tab allows you to cluster your documents into groups based on their similarity.
- Enter the documents you want to cluster.
- Click the Cluster documents button to generate clusters.
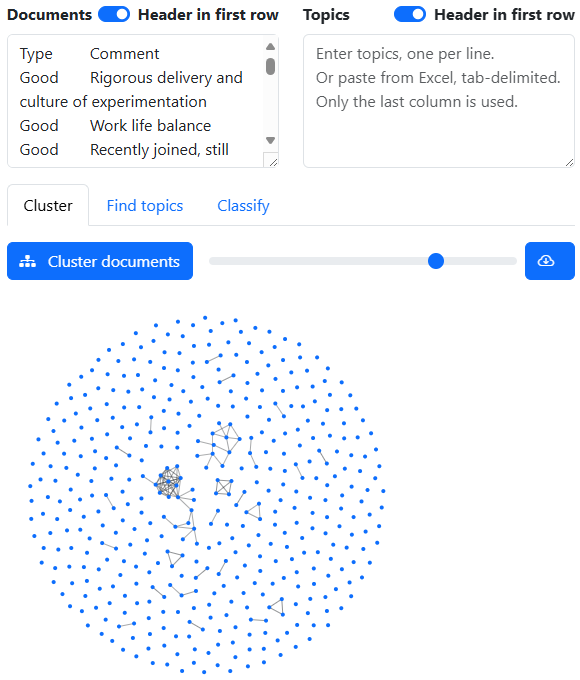
This creates a network graph of documents. Each document is shown as a blue circle. Similar documents are connected.
The cutoff slider filters connects all nodes above a certain similarity score. This helps visually identify cluster or similar documents.
You can interact with the network by:
- Brush over a set of nodes to see the documents they represent.
- Drag a node to move and pin it.
- Double-click a node to un-pin it.
- Double-click a blank area to un-pin all nodes.
Export CSV downloads the network similarity graph as a CSV file. The rows and columns are the documents. Each cell contains the similarity score between the two documents.
Find Topics
This tab is used to automatically discover topics within your documents and name them.
- Enter the documents you want to find topics for.
# of topics: How many topics do you want to find? Pick a number (between say 1 - 50).- We then use K-Means clustering to group the documents into this number of topics.
- If you need more granular clusters, increase the number of topics.
Model for naming: Pick the LLM that will be used to name each of these topics. Almost any model would work well here. Pick the least expensive 🟢 model first.Prompt for naming clusters: This has the instruction given to the LLM to name each topic. Modify this to change the style of naming. For example:- "Suggest detailed descriptions of what each cluster talks about."
- "List the most approprite category from the Dewey Decimal Classification."
Name topics using: Passing EVERY document to the LLM to name the topic is slow and expensive. So we pick the most representative documents. A number between 1-10 is good.Truncate sample at: Some documents are long. It might exhaust the context window. We truncate each document at 200 characters by default. Increase it if you need more context.
Click the Find Topics button. This will cluster the documents and then name them. It will also OVERWRITE the Topics textbox with the newly named topics.
Click Reset to clear the documents and settings and start over.
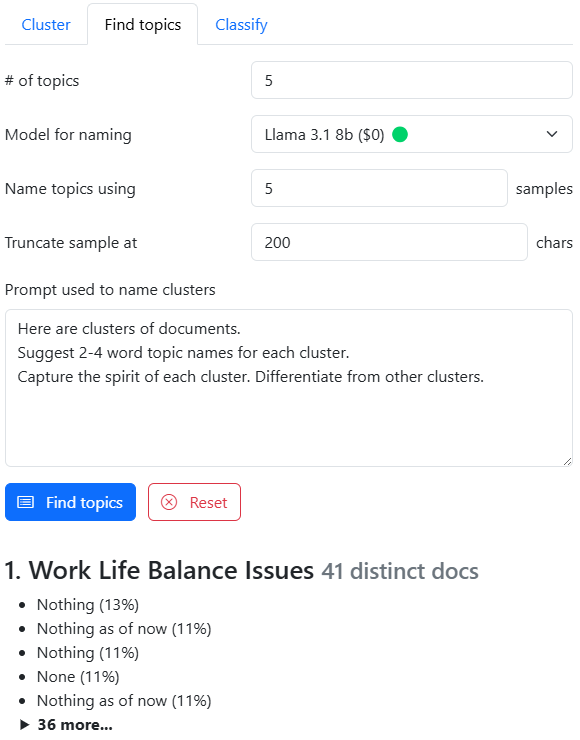
This shows a list of topics. Each topic has:
- The name generated by the LLM
- The number of distinct documents in this topic
- The 5 most representative documents in topic, along with a similarity score in brackets
- A collapsible list of the rest of the documents in this topic
Classify
This tab is used to classify your documents into the provided topics using embeddings.
- Select the Embed Model. The default model is generally good enough. Change if you know what you're doing.
- Click Classify to start the classification process.
Click Reset to clear the documents and settings and start over.
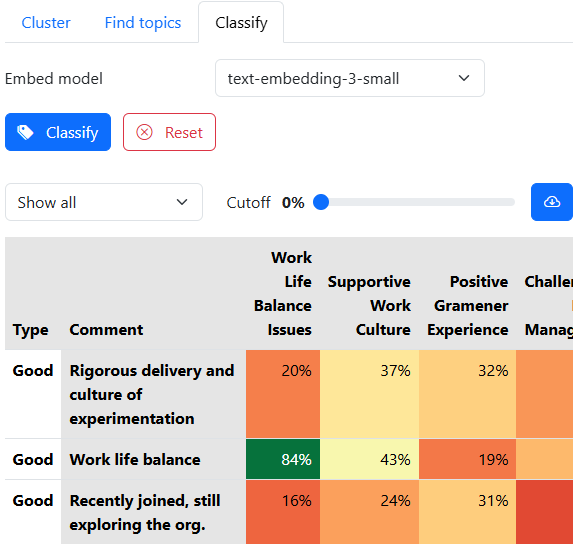
This shows a table where:
- Rows are [documents](#documents]. If multiple columns were provided, all columns are shown.
- Columns are topics. Clicking a column header sorts by similarity to that topic.
- Cells are similarity scores. Higher scores indicate a stronger similarity between the document and topic.
- There is no intrinsic meaning to the scores. Only comparisons are useful.
- Cells are colored green for higher scores, yellow for medium scores, and red for lower scores.
- Hovering on the cell shows the rank of the topic for that document. Rank #1 means that this topic is the most similar to the document.
The cutoff slider filters all cells below a certain similarity score. This helps focus on the best topic matches.
There is a dropdown with options:
- Show all: This shows all values in the table.
- Show only best topic. This only the most similar topic for each document.
- Show top 2 topics. This shows the 2 most similar topics for each document.
Export CSV downloads the table as a CSV file.