Speak
LLM Foundry's Speak Tool allows you to generate audio from text using multiple models, voices, and formats.
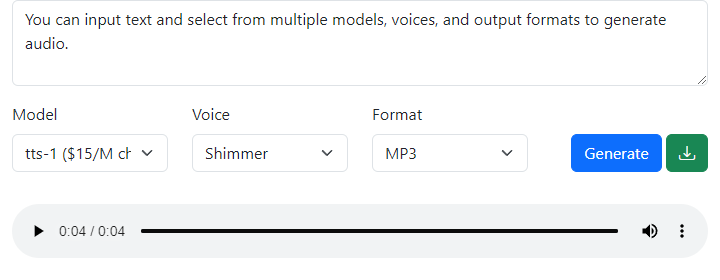
Input
Enter the text you want to convert into audio in the textarea. This text will be synthesized into speech using the chosen model and voice.
Examples:
- "Welcome to the future of text-to-speech technology."
- "Please provide your feedback after the beep."
Model
Select the text-to-speech model. Available options:
- tts-1 ($15/M characters) - Standard quality model
- tts-1-hd ($30/M characters) - High-definition model
Voice
Choose from six available voice profiles:
- Alloy
- Echo
- Fable
- Onyx
- Nova
- Shimmer
Format
Select the audio format for the output. Currently supported streaming formats:
- MP3 (default)
- WAV
- Other formats like Opus, FLAC, WAV and PCM are not streamed on browsers, yet.
Controls
- Generate: Click to create audio from your text using the selected options
- Download: After generation, click to save the audio file locally. The filename will be based on your input text
- Audio Player: Use the built-in controls to play, pause, and seek through the generated audio
The form state is automatically saved between sessions for convenience.