Transcribe
LLM Foundry's Transcribe Tool helps you transcribe, i.e. convert speech to text, from audio
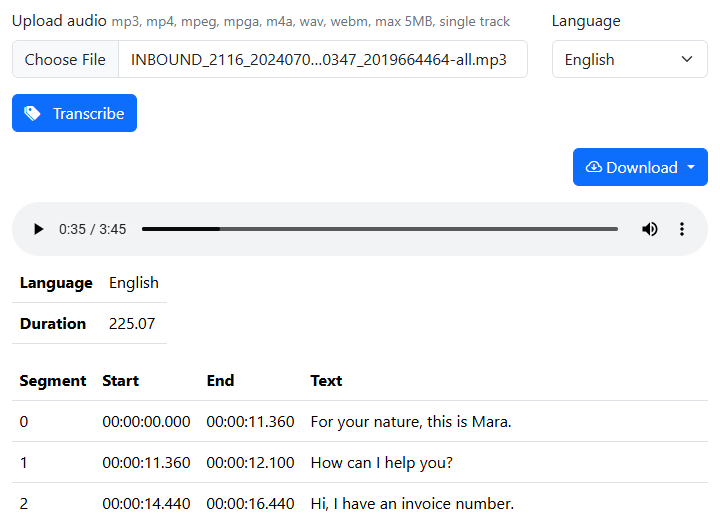
Upload Audio
This field allows users to upload an audio file for transcription. Supported formats include mp3, mp4, mpeg, mpga, m4a, wav, and webm. The maximum file size is 5MB, and it should be a single track.
Click on "Choose File" and select your audio file from your computer. Ensure that your file is within the size limit and is in one of the supported formats.
Language
This dropdown menu allows users to select the language of the audio file being uploaded. You can choose from almost 200 languages. The default language is English.
Select the appropriate language from the list. This helps the transcription model to accurately transcribe the audio.
Transcribe
This button initiates the transcription process for the uploaded audio file.
After uploading the audio file and selecting the language, click the "Transcribe" button to start the transcription. The transcription process will begin, show a loading icon, and the results will be displayed below.
Download
This button provides options to download the transcription in various formats (TXT, VTT, SRT, JSON).
Click the "Download" button, and select the desired format from the dropdown menu. The transcription will be downloaded in the chosen format.
Audio Player
This control allows users to play the uploaded audio file directly from the interface.
Use the play, pause, and seek functions to listen to the audio file. This helps in verifying the accuracy of the transcription.
Transcription Result
This section displays the transcription results once the process is complete. It includes details such as language, duration, and segments of the transcribed audio. Each segment includes the segment ID (0, 1, 2, ...), start and end times, and the transcribed text.
Review each segment for detailed transcription. Click on any row in the transcription table to jump to the corresponding time in the audio player. This feature helps in quickly locating and listening to specific parts of the transcription.