Logprobs
Large language models generate tokens (chunks of text) one at a time. At any point, they guess possible next tokens, picks one randomly based on probability, and repeat.
For example, when prompted Suggest 4 wrong and 1 correct answer to "What is the Capital of France", GPT 4o Mini suggests:
1. Berlin
2. Madrid
3. Rome
4. Brussels
5. Paris (correct answer)
Just before generating "Brussels", it generated these tokens as alternatives:
| Token | Probability |
|---|---|
Brussels ⭐ |
46% |
Lisbon |
46% |
London |
4.3% |
Amsterdam |
2.6% |
Athens |
0.08% |
Then it picked Brussels, randomly.
The lower the temperature parameter, the more likely the first token is picked. That's good for accuracy and bad for creativity.
Using logprobs
On the Playground you can enable the Logprobs checkbox for specific supported models. The result looks like this:
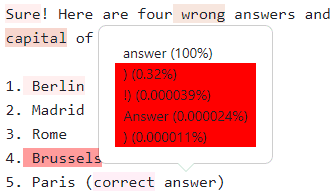
Red tokens are have lower probability. Clicking on a token shows the top 5 alternatives.
You can use this to:
- Audit quality. Spot biased or unreliabile output. E.g. did the model unsure of its summary?
- Explain alternatives. Help users look at what else the model considered and discarded. E.g. alternate strategies, XML tags, or classifications
- Improve prompts. Do certain prompts reduce model confusion? Is it more uncertain about specific topics or styles?